

毫无疑问, AI 的出现,让不少行业面临着技术革新,音乐圈子也不例外不仅人声模拟,在音乐创作这块儿, AI 也是卯足了劲,各种文本生成音乐模型是一个接着一个:像是 OpenAI 的 MuseNet 、谷歌的 MusicLM 、 meta 的 MusicGen ,还有前不久 Stability AI 家刚出来的 Stable Audio 等等等等。
这还只是一些比较出圈的 AI 音乐模型,其他的不知名的更是海了去了。

广告胆小者勿入!五四三二一...恐怖的躲猫猫游戏现在开始!×这么多生成音乐的 AI 模型,它们主打的,都是一个让音乐门外汉也能作曲,只要动动手会打字、会描述就 OK 了这么一说,让没什么乐理知识的世超着实很心动,作曲咱不会,但文字描述可是咱擅长的领域。
于是,我们决定亲自试试目前市面上比较出圈的几款 AI 作曲模型,看看它们到底能不能实现从零作曲,以及写出来的曲子到底好不好听、符不符合要求首先出场的是 Stability AI 的新作曲 AI :Stable Audio 。

官方说是用了超过 80 万个音频文件去训练模型,里面像音乐、音效、单一乐器演奏等都有包含,整个数据集的时长加起来有 19500 多个小时并且光靠语言描述, AI 就能生成最长 90 秒的音乐风格跨度也是贼大,世超去它们官网听了下示例,有钢琴、架子鼓这种单纯器乐的。
还有不同流派不同风格的,比如民族打击乐、嘻哈、重金属之类的甚至还能生成白噪音,像是一个餐馆里嘈杂的吵闹声, u1s1 听起来还蛮逼真的people-talk-in-a-busy-restaurant,差评,45秒
当然,官方公布的肯定都是挑比较好的演示展示出来,到底用起来怎么样还是得亲自上手试试于是我们也注册了号,看看我这个音乐门外汉通过这个模型能创作出什么样的音乐来由于是刚发布,世超还花了好一会儿时间才进到 Stable Audio 的使用网页。

广告从秘书起步,十年内无人超越,以一己之力力挽狂澜成就一段传奇×进去之后,我们先让它生成一段 30 秒的贝斯 solo , 112 个节拍,要 funk ,有律动一点。
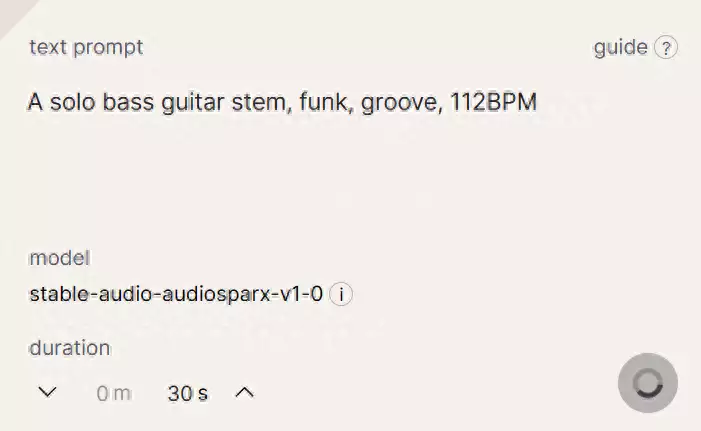
生成过程大概用了一两分钟,世超听了下结果,倒是有点出乎意料,是在弹贝斯没错,音乐风格也挺准确,但唯一的瑕疵就是这贝斯的音色不太清晰,像是指弹和 slap 的中间态接下来上点难度,乐器复杂点,让它生成一段朗朗上口的流行舞曲,中间带着热带打击乐,要有欢快的节奏,适合在沙滩上听。
这次 Stable Audio 有点小失误,虽然节奏挺欢快的,也挺适合在沙滩蹦跶的,但提示词里的热带打击乐,我愣是没在这 30s 听出来再让它生成一段摇滚曲风的音乐,也是不出几分钟就搞定了,虽然听起来依旧不怎么清晰,但摇滚曲风以及电吉他、架子鼓的声音还是能听出来的。
整体体验下来,在音乐生成这块, Stable Audio 的表现确实没有什么大错,偶尔还会有一些出乎意料的表现起码对于一些想给短视频插背景音乐的创作者来说,这个完全够用了并且这次, Stable Audio 还专门在时长上下了一点功夫,普通版可以生成 45 秒以内的音频,想要更长的话,就升级个 PRO 版,可以连续生成 90 秒。
接下来上第二位选手:meta AI 的MusicGen ,它基于 Transformer 架构,靠上一段音频预测生成之后的音频片段现在 MusicGen 只公布了 Demo ,能在 huggingface 上浅浅体验一波。
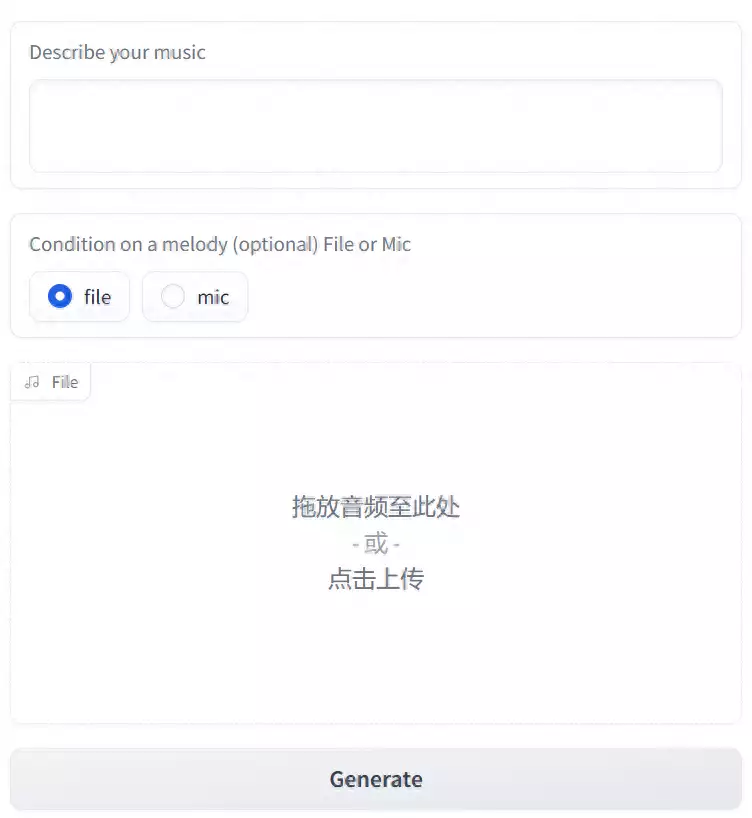
比如说生成一段嘻哈曲风的音乐,听起来很抓耳,节奏倒是蛮干净利落的和 Stable Audio 不太一样的是, MusiacGen 在生成音乐时,提示词会更自由一点,不仅有文字的选项,还可以补充一些声音文件。
操作起来很简单,输入提示词,再把想参考的音乐片段直接拖到文件框内,或者现场录音,当然音频提示也可以不填。
虽然 MusiacGen 一次最长只能生成 30s 的音频,但有音频提示的加成,生成一段长音频也不是不可能,就是会有点麻烦只要每次生成 30s 的音频后,前后截取 10s 作为之后的提示,最后拼接起来就是一段长音频了。
不过在整个体验过程中,有一点着实会劝退一大波人,那就是它生成的速度实在是太慢了,三四分钟还算好的,离谱的是有时等了好几分钟,结果突然弹出个崩溃了的弹窗。。。

今年年初,谷歌也发布了音乐大模型 MusicLM ,在现有的作曲 AI 中,谷歌的这个功能最多除了最基础的文字生成音乐之外, MusicLM 还搞了一些其他花样比如说故事模式,可以让它生成一段 1 分钟长的音乐: 0~15s 冥想、 16~30s 醒来、 31~45s 跑步、 46~60s 结束。
生成的音频听起来确实还挺符合要求的,但就还是老毛病,乐器的声音不够清晰,各个段落之间的转换也有点生硬还有看图配乐的功能,给出一个经典的拿破仑骑马穿越阿尔卑斯山的图,再对图片进行一些描述, MusicLM 就能给生成 30s 的配乐。

这次听起还真有点戏剧的感觉。MusicLM 同样没有对外公布,想要体验只能在 AI Test Kitchen 上排队获取内测资格。

OpenAI 的 MuseNet ,在三年前就已经在官网公布了。

不过最近这几年倒是没怎么更新,还是基于和 GPT-2 一样的技术并且 3 年过去了,这个 AI 还没有对外开放使用但看看它官网对 MuseNet 的介绍以及给出的示例,估摸着出来就是吊打上面模型的存在先不说生成音乐的质量,就光是时长就已经很顶了,最多可以生成 4 分钟的音乐。
对比上面提到的几个模型,生成音乐的质感也是分分钟秒杀,世超从官网下载了个示例,大家可以一起听听不说是 AI 创作的,我还真会以为是那个音乐大师编的新曲子,有引入、有高潮,乐器的声音也很清晰,再简单调整下就是个完整的音乐作品了。
当然,有这样的效果除了有神经网络的功劳外,训练用的数据集也是起到关键作用的OpenAI 统共用了数十万个 MIDI 文件训练 MuseNet ,下面这张图就是用到的部分数据集,从肖邦、巴赫、莫扎特到迈克 · 杰克逊、披头士、麦当娜,从古典到摇滚到流行,几乎各种风格的音乐都能在里面找到。

不止国外,国内这几年 AI 音乐也是发展得火热,去年华为开发者大会上,就公布了一款音乐 AI :Singer 模型,网易云面向音乐人推出了网易天音,作词、作曲、编曲直接都能靠 AI 解决。

在前不久的 2023 世界人工智能大会上,腾讯多媒体实验室也展示了自研的 AI 通用作曲框架 XMusic 。
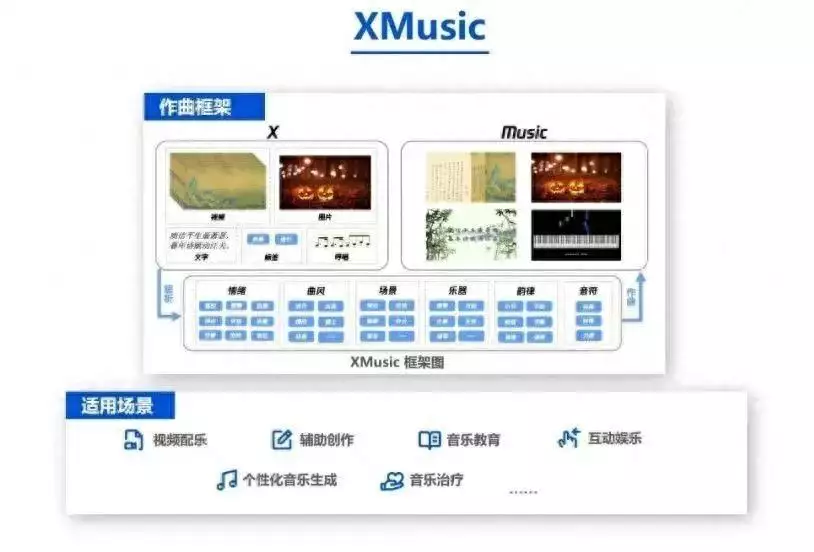
总的来说,这几个 AI 作曲模型也算是各有千秋,想要的音乐风格基本都能生成,甚至有时生成的音乐不仔细琢磨还真听不出来是 AI 生成的,用在一些短视频中也是能妥妥地 “ 蒙混 ” 过去但若要以一个专业人士来看的话,上面这些 AI 恐怕都或多或少有些缺点,最明显的就是上面提到的那几个 AI ,它们生成的音乐在乐器演奏上几乎都不太清晰。
并且,和 AI 作画一样, AI 音乐也是版权问题的一大重灾区,由于相关法律还跟不上 AI 发展的速度,时不时就有 AI 侵权的官司比如今年 1 月份,美国唱片业协会向政府提交了一份侵权报告,提醒他们要重视 AI 音乐侵权的问题。

就连 MusicLM 的研究人员也亲口承认了侵权问题,在论文中写到会有盗用创意内容的潜在风险原因是在试验这个模型的过程中,发现它在生成的音乐里,大概有 1% 是直接从训练的数据集中照搬过来的也难怪现在大多音乐 AI 模型要么干脆不对外试用,要么只有 demo 或者排队内测,就连对外开放的 Stable Audio 也是反复强调自己的数据集是经过 AudioSparx 授权的。
抛开版权问题不说,目前 AI 在音乐这块的发展确实是令人咋舌,拥抱 AI 音乐也已经是行业内的大势所趋像专门提供轻音乐的 AI 音乐公司 Endel ,已经先后得到了华纳、索尼等音乐巨头的投资, AI 音乐创作平台 Soundful 也拿到了环球音乐、迪士尼、微软的投资。

当然,入局 AI 音乐是出于商业以及科技趋势的考量,在音乐性与艺术性上,目前的 AI 还是远不及人类创作者的,而这也是未来 AI 最应该优先考虑的。
